.png)
- 2026년 05월 01일 금요일






인텔은 메타(Meta)의 최신 LLM(대규모 언어 모델)인 라마 3.1(Llama 3.1)에 데이터센터, 엣지 및 클라이언트 AI 제품 전반에 걸친 성능 데이터 및 최적화를 제공한다고 밝혔다. 인텔은 ‘AI 에브리웨어’ 전략을 위해 AI 소프트웨어 생태계에 지속적으로 투자하고 있으며, 새로운 모델이 인텔의 AI 하드웨어에 최적화되도록 보장하고 있다.
메타는 지난 4월 라마 3 출시에 이어, 지난 23일(현지 시각) 현재까지 가장 성능이 뛰어난 모델인 라마 3.1을 출시했다. 라마 3.1은 공개적으로 사용 가능한 가장 큰 파운데이션 모델인 라마 3.1 405B(4천 50억개 모델)를 포함해 다양한 규모와 기능에서 여러 새로운 업데이트 모델을 제공한다. 이 새로운 모델들은 파이토치(PyTorch) 및 인텔® 파이토치 익스텐션(Intel® Extension for PyTorch), 딥스피드(DeepSpeed), 허깅 페이스 옵티멈 라이브러리(Hugging Face* Optimum libraries), vLLM 등 개방형 생태계 소프트웨어를 통해 인텔 AI 제품에서 활성화 및 최적화된다. 또한 생태계 전반에서 최고의 혁신을 활용하는 개방형, 멀티 벤더, 강력하고 컴포저블한 생성형AI 솔루션을 만들기 위한 LF AI 및 데이터 재단(LF AI & Data Foundation)의 새로운 오픈 플랫폼 프로젝트인 OPEA(Open Platform for Enterprise AI) 역시 이 모델들을 지원한다.
라마 3.1 다국어 LLM 컬렉션은 8B, 70B, 405B 크기(텍스트 인/텍스트 아웃)의 사전 학습 및 조정(인스트럭션 튜닝)된 생성 모델 컬렉션으로, 모든 모델은 8개 구술어에 걸쳐 긴 컨텍스트 길이(128k)를 지원한다. 라마 3.1 405B는 일반 지식, 조작성, 수학, 도구 사용 및 다국어 번역에 있어 최첨단 기능을 갖추고 있다. 이를 통해 커뮤니티는 합성 데이터 생성 및 모델 증류(model distillation)와 같은 새로운 기능을 활용할 수 있게 될 것이다.
인텔® 가우디®(Intel® Gaudi®) 및 인텔® 제온®(Intel® Xeon®), 인텔® 코어™ Ultra(Intel® Core™ Ultra) 프로세서 및 인텔® 아크™(Intel® Arc™) 그래픽이 탑재된 AI PC를 포함해 인텔 AI 제품 포트폴리오 상에서의 라마 3.1 모델 초기 성능 측정 결과는 다음과 같다.
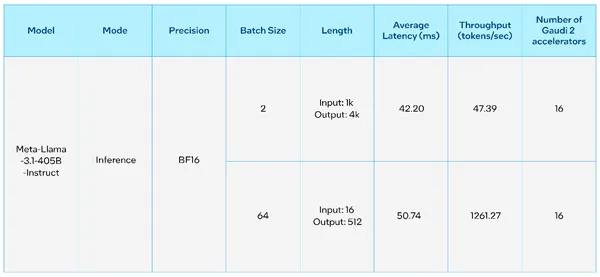
인텔® 가우디® AI 가속기는 생성형 AI 및 대형 언어 모델(LLM)의 고성능 가속을 위해 설계되었다. 아래 표는 새로운 라마 3.1 70B 및 405B 모델에 대한 추론 성능을 제공하는 인텔 가우디 2의 성능 측정치를 나타낸다. 405B 모델의 초기 성능 측정은 각 8개의 가우디 2 가속기를 갖춘 두 노드에서 수행되었다. 인텔 가우디 소프트웨어의 성숙성 덕분에 사용자는 새로운 라마 3.1 모델을 쉽게 실행하고 빠르게 추론 결과를 생성할 수 있다.
인텔® 제온® 프로세서는 일반 컴퓨팅의 유비쿼터스 백본으로, 전 세계적으로 강력한 컴퓨팅 자원에 쉽게 접근할 수 있다. 현재 모든 주요 클라우드 서비스 제공업체에서 사용 가능한 인텔 제온 프로세서는 AI 성능을 새로운 수준으로 끌어올린 AI 엔진, ‘인텔® 어드밴스드 매트릭스 익스텐션(Intel® Advanced Matrix Extensions, AMX)’을 모든 코어에 탑재하고 있다. 벤치마킹 결과에 따르면, 1천 개의 토큰 입력 및 128개의 토큰 출력으로 라마 3.1 8B 모델을 실행하면 5세대 인텔® 제온® 플랫폼에서 초당 176개의 토큰 처리량을 달성할 수 있으며, 토큰의 지연 시간을 50ms 이하로 유지할 수 있다. 아래 그림 1에서는 12만 8천 개의 토큰 컨텍스트 길이를 라마 3.1 8B 모델로 지원할 때 지연 시간이 100ms 이하로 유지될 수 있음을 확인할 수 있다.
인텔® 코어™ Ultra 프로세서와 인텔® 아크™ 그래픽이 탑재된 AI PC는 클라이언트와 엣지에서 뛰어난 온디바이스 AI 추론 성능을 제공한다. 인텔® 코어 플랫폼의 NPU와 아크 GPU의 인텔® Xe 매트릭스 익스텐션 가속과 같은 특화된 AI 하드웨어를 통해 AI PC에서 경량화된 파인튜닝 및 애플리케이션 맞춤화가 그 어느 때보다 쉬워졌다. 로컬 연구 개발을 위해 파이토치(PyTorch) 및 인텔 파이토치 익스텐션(Intel Extension for PyTorch)과 같은 개방형 생태계 프레임워크가 활성화되고 가속화되었다. 생산 단계에서는 인텔의 오픈비노(OpenVINO™) 툴키트를 활용하여 AI PC에서 효율적인 모델 배포 및 추론을 수행할 수 있다. AI 워크로드는 최적의 성능을 위해 CPU, GPU, NPU 간에 원활하게 배포될 수 있다.
인텔의 AI 플랫폼과 솔루션은 엔터프라이즈용 AI RAG 배포를 가속화한다. OPEA의 창립 회원 중 하나인 인텔은 엔터프라이즈용 AI를 위한 개방형 생태계 구축에 앞장서고 있다. OPEA가 라마3.1 모델을 활용하여 성능을 최적화했다는 점이 주목할 만하다.
OPEA는 엔터프라이즈용 오픈 소스, 표준화 및 모듈화된 이기종 RAG 파이프라인을 제공한다. 이는 구성 및 설정 가능한 멀티 파트너 요소를 기반으로 구축된다. 이 평가에서는 OPEA 청사진에 마이크로서비스(가드레일, 임베딩, LLM, 데이터 수집, 검색)가 배포되었다. E2E RAG 파이프라인은 LLM 추론에 라마 3.1을 사용하며, 임베딩에는 BAAI/bge-base-en-v1.5가 사용되고, 벡터 DB에는 레디스(Redis)가 사용되며, 오케스트레이션에는 쿠버네티스(K8s)가 사용된다.
제온 시스템에 8개의 가우디 2 카드를 사용하여 OPEA 기반 엔터프라이즈용 RAG 참조 솔루션을 실행한 성능 데이터는 아래에서 확인할 수 있다. 해당 데이터에는 임베딩의 P99 엔드-투-엔드 지연 시간과 초당 생성된 토큰 수, 그리고 LLM에서 128개의 쿼리 토큰에 대한 성능 데이터가 포함되어 있다. 또한, LLM에서 1024개의 입력 토큰 및 출력 토큰에 대한 성능 데이터도 포함되어 있다.
결론적으로, 현재 인텔 AI PC 및 데이터센터 AI 제품 포트폴리오와 솔루션은 라마 3.1을 실행할 수 있으며, OPEA는 인텔 가우디 2 및 제온 제품군에서 라마 3.1을 통해 완전히 활성화되고 있다. 인텔은 새로운 모델과 사용 사례를 지원하기 위해 지속적으로 소프트웨어 최적화를 진행하고 있다.
조지영 기자 miyoujj@noteforum.co.kr
[디지털 모바일 IT 전문 정보 - 노트포럼]
Copyrights ⓒ 노트포럼, 무단전재 및 재배포 금지