.png)
- 2026년 02월 04일 수요일







2016년 7월13일, 인텔 코리아는 양재동 엘타워에서
차세대 제온파이 프로세서 (코드명 :나이츠 랜딩) 을 국내에 발표하는 자리를 마련했다.

방대한 데이터를 분석해 미래를 예측하는 기술인
머신러닝을 구동하기 위해서는 많은 정보를 빠른 시간에 처리할 수 있는 프로세서가 필요하다. 특히 머신러닝은 컴퓨터 스스로 방대한 데이터를 수집,
학습할 수 있도록 설계되어 있으며 빅데이터의 핵심 기술인 인공지능에 활용되고 있어 더 높은 성능은 필수적이라 할 수 있다.
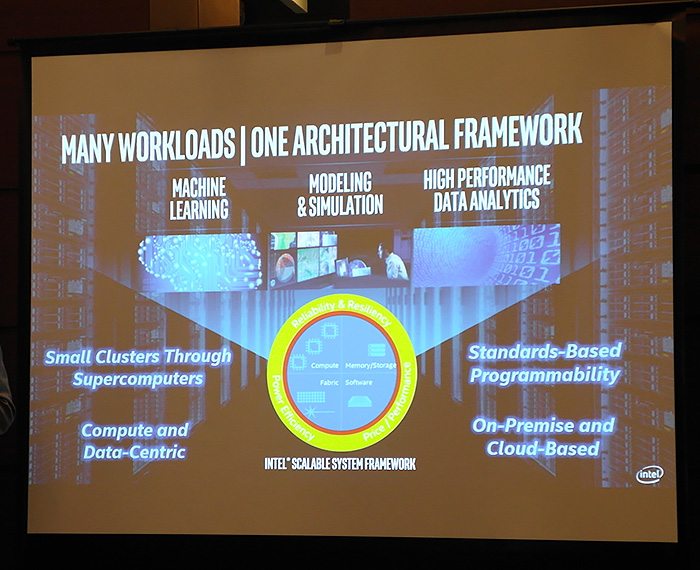
특히 머신러닝 을 구동하는데 사용되는 고성능 컴퓨터
(HPC) 에서 인텔은 확장형 시스템 프레임워크 (SFF)나 개발자 엑세스 프로그램과 같은 다양한 기술과 아키텍처를 선보이고 있다.

* 환영사를 전하고 있는 인텔코리아 윤은경 부사장


이번에 발표된 차세대 제온 파이 프로세서는 뛰어난
효율성과 확장성으로 기반으로 HPC 등의 다양한 환경 및 애플리케이션의 연산을 보다 빠르게 처리해 주는 제품이다.

인텔 제온파이 프로세서는 최대 72개의 코어에 강력한
백터 기능을 갖춰 병렬 컴퓨팅의 성능을 한층 높였으며 데이터센터급의 CPU 확장성과 안정성을 제공한다.
또한 일반적인 프로그래밍 모델 사용을 통해 개발자
기반공유 및 코드 재사용이 가능해져 생산력을 향상 시켰으며 x86 CPU 아키텍처 및 개방형 표준 기반으로 개발이 이루어져 뛰어난 유연성과 높은
이식성, 재사용성을 제공하고 있다.
16GB의 고대역폭 메모리와 결합해 최대 초당 500GB의 메모리 대역폭을 제공하며 옴니패스
아키텍처와 결합하면 솔루션 비용이나 전력소비량 등이 감소된다.
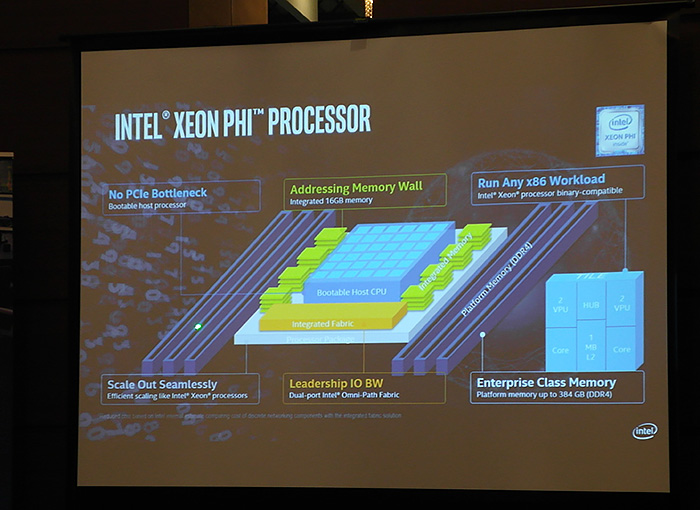
인텔 제온 파이 프로세서는 전작과 달리 부팅이 가능한
호스트 프로세서로 32노드 인프라스트럭처 상에서 GPU보다 최대 1.38배 향상된 확장성을 제공하며, 128 노드 인프라 상에서 인텔 제온 파이
제품군을 사용하면 단일 노드 대비 최대 50배 빠른 속도로 모델을 훈련 시킬 수 있다.
또한 머신러닝을 위한 인프라스트럭처로 가장 많이
채택된2 인텔 제온 프로세서 E5 제품군과 결합해 한층 향상된 성능을 낼 수 있다. 인텔 제온 프로세서 E5 v4 제품군은 머신러닝
스코어링(scoring) 모델에 최적화되어 있으며, 인텔 제온 파이 프로세서와 함께 HPC 및 머신러닝 분야에 최적화된 시스템을 사용자에게
제공한다.

* 차세대 인텔제온 파이 프로세서를 발표한 휴고 살레 인텔 HPC 마케팅 책임자

인텔은 제온 파이 및 제온 프로세서 기반 HPC 시스템
활용을 최적화할 수 있도록 다중 코어에 맞춰 애플리케이션을 병렬화 및 벡터화할 수 있는 교육 과정을 제공한다. 지금까지 총 600명이 프로그램에
참여했으며, 올해 하반기까지 추가로 400명의 전문 인력에 대한 교육을 완료할 예정이다.

한편 같은 장소에 열린고객대상 세미나를 개최해 개발자나
업계종사자 들에게 관련 제품을 홀보하는 시간을 마련했다.
김원영 기자
goora@noteforum.co.kr
[디지털 모바일 IT 전문 정보 - 노트포럼]
Copyrights ⓒ 노트포럼, 무단전재 및 재배포 금지